sample_density =10xs =[[-2.0+4* x/sample_density,-2.0+4* y/sample_density]for x inrange(sample_density+1)for y inrange(sample_density+1)]dataset =[(x, y, o(x, y))for x, y in xs
]
import math
defsigmoid(x):return1/(1+ math.exp(-x))
ニューロン
from random import seed, random
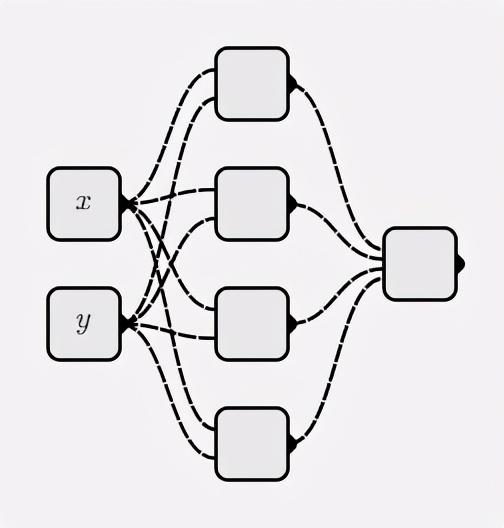
seed(0)classNeuron:def__init__(self, num_inputs): self.weights =[random()-0.5for _ inrange(num_inputs)] self.bias =0.0defforward(self, inputs):# z = wx + b z =sum([ i * w
for i, w inzip(inputs, self.weights)])+ self.bias
return sigmoid(z)
classNeuron:...defforward(self, inputs): self.inputs_cache = inputs
# z = wx + b self.z_cache =sum([ i * w
for i, w inzip(inputs, self.weights)])+ self.bias
return sigmoid(self.z_cache)defzero_grad(self): self.d_weights =[0.0for w in self.weights] self.d_bias =0.0defbackward(self, d_a): d_loss_z = d_a * sigmoid_derivative(self.z_cache) self.d_bias += d_loss_z
for i inrange(len(self.inputs_cache)): self.d_weights[i]+= d_loss_z * self.inputs_cache[i]return[d_loss_z * w for w in self.weights]classMyNet:...defzero_grad(self):for layer in self.layers:for neuron in layer: neuron.zero_grad()defbackward(self, d_loss): d_as =[d_loss]for layer inreversed(self.layers): da_list =[ neuron.backward(d_a)for neuron, d_a inzip(layer, d_as)] d_as =[sum(da)for da inzip(*da_list)]
偏導関数はそれぞれd_weightsとd_biasに格納されます
zero_grad関数は、各偏導関数を含む勾配をクリアするために使用されます
backward関数は、偏導関数を計算し、その値を累積的に格納するために使用されます
パラメータを更新する
最急降下法を使用してパラメーターを更新します。
classNeuron:...defupdate_params(self, learning_rate): self.bias -= learning_rate * self.d_bias
for i inrange(len(self.weights)): self.weights[i]-= learning_rate * self.d_weights[i]classMyNet:...defupdate_params(self, learning_rate):for layer in self.layers:for neuron in layer: neuron.update_params(learning_rate)
トレーニングを実行する
defone_step(learning_rate): net.zero_grad() loss =0.0 num_samples =len(dataset)for x, y, z in dataset: predict = net.forward([x, y]) loss += square_loss(predict, z) net.backward(square_loss_derivative(predict, z)/ num_samples) net.update_params(learning_rate)return loss / num_samples
deftrain(epoch, learning_rate):for i inrange(epoch): loss = one_step(learning_rate)if i ==0or(i+1)%100==0:print(f"{i+1}{loss:.4f}")