A lot of theoretical knowledge have been told before, now it's time to start the practice. Let's try to build a neural network from scratch and train it to string the whole process together.
In order to be more intuitive and easier to understand, we follow the following principles:
Do not use third-party libraries to make the logic simpler;
No performance optimization: avoid introducing additional concepts and techniques, increasing complexity;
Dataset
First, we need a dataset. To facilitate visualization, we use a binary function as the objective function, and then generate the dataset by sampling on it.
Note: In actual engineering projects, the objective function is unknown, but we can sample on it.
Objective function
o(x,y)={10x2+y2<1otherwise
Code show as below:
defo(x, y):return1.0if x*x + y*y <1else0.0
Generate dataset
sample_density =10xs =[[-2.0+4* x/sample_density,-2.0+4* y/sample_density]for x inrange(sample_density+1)for y inrange(sample_density+1)]dataset =[(x, y, o(x, y))for x, y in xs
]
The dataset generated is: [[-2.0, -2.0, 0.0], [-2.0, -1.6, 0.0], ...]
Dataset image
Construct a neural network
Activation function
import math
defsigmoid(x):return1/(1+ math.exp(-x))
Neuron
from random import seed, random
seed(0)classNeuron:def__init__(self, num_inputs): self.weights =[random()-0.5for _ inrange(num_inputs)] self.bias =0.0defforward(self, inputs):# z = wx + b z =sum([ i * w
for i, w inzip(inputs, self.weights)])+ self.bias
return sigmoid(z)
The neuron expression is:
sigmoid(wx+b)
w: vector, corresponding to the weights array in the code
b: corresponds to the bias in the code
Note: The parameters in the neuron are initialized randomly. However, in order to ensure reproducible experiments, a random seed is set(seed(0))
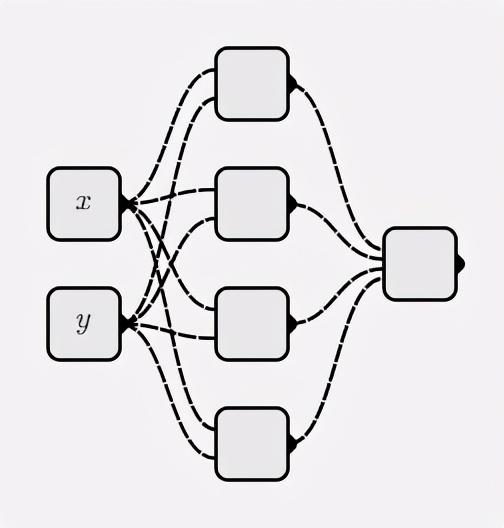
Neural Networks
classMyNet:def__init__(self, num_inputs, hidden_shapes): layer_shapes = hidden_shapes +[1] input_shapes =[num_inputs]+ hidden_shapes
self.layers =[[ Neuron(pre_layer_size)for _ inrange(layer_size)]for layer_size, pre_layer_size inzip(layer_shapes, input_shapes)]defforward(self, inputs):for layer in self.layers: inputs =[ neuron.forward(inputs)for neuron in layer
]# return the output of the last neuronreturn inputs[0]
Construct a neural network as follows:
net = MyNet(2,[4])
At this point, we have got a neural network(net), which can call its neural network function:
print(net.forward([0,0]))
Get the function value 0.55..., the neural network at this time is an untrained network.
The calculation of the gradient is complicated, especially for deep neural networks. Back Propagation Algorithm is an algorithm specifically designed to calculate the gradient of a neural network.
Due to its complexity, it will not be described here. Those interested can refer to the following detailed code. Moreover, the current deep learning framework has the function of automatically calculating the gradient.
Find the partial derivative (part of the data is cached in the forward function to facilitate the derivative):
classNeuron:...defforward(self, inputs): self.inputs_cache = inputs
# z = wx + b self.z_cache =sum([ i * w
for i, w inzip(inputs, self.weights)])+ self.bias
return sigmoid(self.z_cache)defzero_grad(self): self.d_weights =[0.0for w in self.weights] self.d_bias =0.0defbackward(self, d_a): d_loss_z = d_a * sigmoid_derivative(self.z_cache) self.d_bias += d_loss_z
for i inrange(len(self.inputs_cache)): self.d_weights[i]+= d_loss_z * self.inputs_cache[i]return[d_loss_z * w for w in self.weights]classMyNet:...defzero_grad(self):for layer in self.layers:for neuron in layer: neuron.zero_grad()defbackward(self, d_loss): d_as =[d_loss]for layer inreversed(self.layers): da_list =[ neuron.backward(d_a)for neuron, d_a inzip(layer, d_as)] d_as =[sum(da)for da inzip(*da_list)]
Partial derivatives are stored in d_weights and d_bias respectively
The zero_grad function is used to clear the gradient, including each partial derivative
The backward function is used to calculate the partial derivative and store its value cumulatively
Update parameters
Use gradient descent method to update parameters:
classNeuron:...defupdate_params(self, learning_rate): self.bias -= learning_rate * self.d_bias
for i inrange(len(self.weights)): self.weights[i]-= learning_rate * self.d_weights[i]classMyNet:...defupdate_params(self, learning_rate):for layer in self.layers:for neuron in layer: neuron.update_params(learning_rate)
Perform training
defone_step(learning_rate): net.zero_grad() loss =0.0 num_samples =len(dataset)for x, y, z in dataset: predict = net.forward([x, y]) loss += square_loss(predict, z) net.backward(square_loss_derivative(predict, z)/ num_samples) net.update_params(learning_rate)return loss / num_samples
deftrain(epoch, learning_rate):for i inrange(epoch): loss = one_step(learning_rate)if i ==0or(i+1)%100==0:print(f"{i+1}{loss:.4f}")
Training 2000 steps:
train(2000, learning_rate=10)
Note: A relatively large learning rate is used here, which is related to the project situation. The learning rate in actual projects is usually very small
Neural network function image after training
log y
The loss curve
Inference
After training, the model can be used for inference:
Sampling on o(x,y) to get the dataset, that is, the dataset function: d(x,y)
Constructed a fully connected neural network with a hidden layer, that is, neural network function: f(x,y)
Use the gradient descent method to train the neural network so that f(x,y) approximates d(x,y)
The most complicated part is to find the gradient, which uses the back-propagation algorithm. In actual projects, using mainstream deep learning frameworks for development can save the code for gradients and lower the threshold.
In the laboratory's 3D classification experiments, the second dataset is very similar to the one in this practice, so you can go in and operate it.