Segmentação de palavras, marcação POS e agrupamento
Marcação de sequência em ação
RNN bidirecional
BI-LSTM-CRF
Atenção
Modelos de Linguagem
Modelo de n-grama: Unigrama
Modelo de n-grama: Bigrama
Modelo de n-grama: Trigrama
Modelo de Linguagem RNN
Modelo de Linguagem Transformer
Álgebra Linear
Vetor
Matriz
Mergulhe na multiplicação de matrizes
Tensor
Mergulhe no neurônio
Visão geral
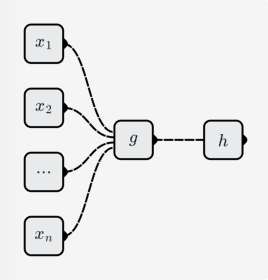
Na seção anterior (O que é rede neural), aprendemos que uma rede neural é uma função, que é composta de neurônios, e neurônio também é uma função.
O neurônio pode continuar a ser dividido em 2 subfunções:
n função linear do elemento: g(x1,...,xn)
função não linear unária: h(x)
A função representada pelo neurônio é:
f(x1,...,xn)=h(g(x1,...,xn))
Função linear g(x1,...,xn)
A função linear tem a seguinte forma:
g(x1,...,xn)=w1x1+...,wnxn+b
Entre eles, w1,...,wn,b são todos parâmetros, e diferentes funções lineares possuem parâmetros diferentes.
Função linear unária
Quando n=1, g(x1)=w1x1+b, a imagem da função é uma linha reta:
w11
b0
Função linear binária
Quando n=2, g(x1,x2)=w1x1+w2x2+b, a imagem da função é um plano:
w10
w21
b0
Função linear do elemento n
Quando n>2, a imagem da função é um hiperplano. Além do 3D, a visualização não é conveniente. Mas você pode imaginar que sua característica é reta.
Função não linear h(x)
É fácil entender pelo nome que uma função não linear é uma função diferente de uma função linear. Uma função linear é reta e uma função não linear é curva. Como a função sigmoid mais comum:
Função de ativação
Em redes neurais, chamamos essa função não linear unária de função de ativação. Para algumas funções de ativação comuns, consulte função de ativação na base de conhecimento, onde:
Linear: f(x)=x é uma função linear, o que significa que uma função não linear não é usada
Softmax é um caso especial. Estritamente falando, não é uma função de ativação
Necessidade
Por que uma função de ativação não linear deve ser seguida por uma função linear?
Isto é porque:
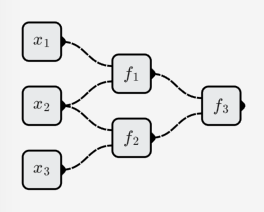
Se todos os neurônios são funções lineares, então a rede neural composta de neurônios também é uma função linear.
Como o exemplo a seguir:
f1(x,y)=w1x+w2y+b1
f2(x,y)=w3x+w4y+b2
f3(x,y)=w5x+w6y+b3
Então a função representada por toda a rede neural é:
A função objetivo que precisamos construir contém várias funções, e a função linear é apenas uma delas.
Esperamos que as redes neurais possam simular funções arbitrárias, não apenas funções lineares. Então adicionamos uma função de ativação não linear e "dobramos" a função linear.
Neurônio completo
O neurônio completo combina uma função linear e uma função de ativação não linear, tornando-o mais interessante e poderoso.
Função unária
Quando n=1, g(x1)=w1x1+b, usando a função de ativação sigmoid, a função correspondente do neurônio é:
h(g(x))=sigmoid(wx+b)
A imagem da função é:
w1
b0
Função binária
Quando n=2, g(x1,x2)=w1x1+w2x2+b, usando a função de ativação sigmoid, a função correspondente do neurônio é:
h(g(x))=sigmoid(w1x1+w2x2+b)
A imagem da função é:
w10
w21
b0
n-função do elemento
Devido ao problema de visualização, cabe inteiramente à minha imaginação aqui! 😥
Pergunta
Por que a rede neural pode simular funções complexas a partir da combinação de neurônios?
Você pode imaginar intuitivamente como simular uma função um pouco mais complicada por meio de neurônios simples.