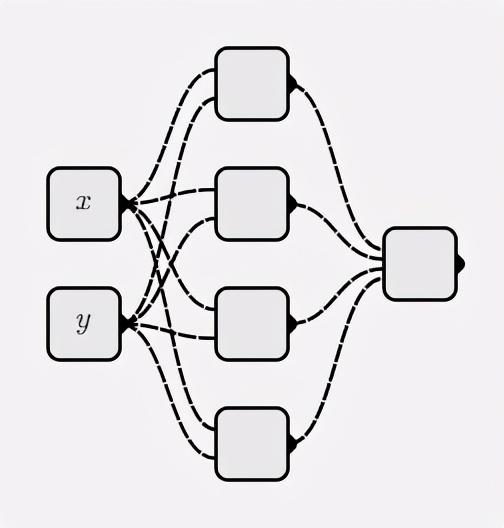
많은 이론적 지식이 이전에 설명되었으므로 이제 실습을 시작할 때입니다. 신경망을 처음부터 구축하고 전체 프로세스를 함께 묶도록 훈련해 봅시다.
보다 직관적이고 이해하기 쉽도록 다음 원칙을 따릅니다.
로직을 단순화하기 위해 타사 라이브러리를 사용하지 마십시오.
성능 최적화 없음: 추가 개념 및 기술 도입을 피하여 복잡성을 증가시킵니다.
데이터세트
먼저 데이터 세트가 필요합니다. 시각화를 용이하게 하기 위해 이진 함수를 목적 함수로 사용하고 샘플링하여 데이터 세트를 생성합니다.
참고: 실제 엔지니어링 프로젝트에서는 목적 함수를 알 수 없지만 샘플링할 수 있습니다.
목적 함수
o(x,y)={10x2+y2<1그렇지않으면
코드 쇼는 아래와 같습니다.
defo(x, y):return1.0if x*x + y*y <1else0.0
데이터세트 생성
sample_density =10xs =[[-2.0+4* x/sample_density,-2.0+4* y/sample_density]for x inrange(sample_density+1)for y inrange(sample_density+1)]dataset =[(x, y, o(x, y))for x, y in xs
]
생성된 데이터 세트는 [[-2.0, -2.0, 0.0], [-2.0, -1.6, 0.0], ...]
데이터세트 이미지
신경망 구축
활성화 기능
import math
defsigmoid(x):return1/(1+ math.exp(-x))
뉴런
from random import seed, random
seed(0)classNeuron:def__init__(self, num_inputs): self.weights =[random()-0.5for _ inrange(num_inputs)] self.bias =0.0defforward(self, inputs):# z = wx + b z =sum([ i * w
for i, w inzip(inputs, self.weights)])+ self.bias
return sigmoid(z)
뉴런 표현은 다음과 같습니다.
sigmoid(wx+b)
w: 벡터, 코드의 가중치 배열에 해당
b: 코드의 편향에 해당합니다.
참고: 뉴런의 매개변수는 무작위로 초기화됩니다. 그러나 재현 가능한 실험을 위해 임의의 시드가 설정됩니다(seed(0))
신경망
classMyNet:def__init__(self, num_inputs, hidden_shapes): layer_shapes = hidden_shapes +[1] input_shapes =[num_inputs]+ hidden_shapes
self.layers =[[ Neuron(pre_layer_size)for _ inrange(layer_size)]for layer_size, pre_layer_size inzip(layer_shapes, input_shapes)]defforward(self, inputs):for layer in self.layers: inputs =[ neuron.forward(inputs)for neuron in layer
]# 마지막 뉴런의 출력을 반환return inputs[0]
classNeuron:...defforward(self, inputs): self.inputs_cache = inputs
# z = wx + b self.z_cache =sum([ i * w
for i, w inzip(inputs, self.weights)])+ self.bias
return sigmoid(self.z_cache)defzero_grad(self): self.d_weights =[0.0for w in self.weights] self.d_bias =0.0defbackward(self, d_a): d_loss_z = d_a * sigmoid_derivative(self.z_cache) self.d_bias += d_loss_z
for i inrange(len(self.inputs_cache)): self.d_weights[i]+= d_loss_z * self.inputs_cache[i]return[d_loss_z * w for w in self.weights]classMyNet:...defzero_grad(self):for layer in self.layers:for neuron in layer: neuron.zero_grad()defbackward(self, d_loss): d_as =[d_loss]for layer inreversed(self.layers): da_list =[ neuron.backward(d_a)for neuron, d_a inzip(layer, d_as)] d_as =[sum(da)for da inzip(*da_list)]
편도함수는 d_weights 및 d_bias에 각각 저장됩니다.
zero_grad 함수는 각 편미분을 포함하여 기울기를 지우는 데 사용됩니다.
backward 함수는 편도함수를 계산하고 그 값을 누적 저장하는 데 사용됩니다.
매개변수 업데이트
경사 하강법을 사용하여 매개변수 업데이트:
classNeuron:...defupdate_params(self, learning_rate): self.bias -= learning_rate * self.d_bias
for i inrange(len(self.weights)): self.weights[i]-= learning_rate * self.d_weights[i]classMyNet:...defupdate_params(self, learning_rate):for layer in self.layers:for neuron in layer: neuron.update_params(learning_rate)
훈련 수행
defone_step(learning_rate): net.zero_grad() loss =0.0 num_samples =len(dataset)for x, y, z in dataset: predict = net.forward([x, y]) loss += square_loss(predict, z) net.backward(square_loss_derivative(predict, z)/ num_samples) net.update_params(learning_rate)return loss / num_samples
deftrain(epoch, learning_rate):for i inrange(epoch): loss = one_step(learning_rate)if i ==0or(i+1)%100==0:print(f"{i+1}{loss:.4f}")
훈련 2000단계:
train(2000, learning_rate=10)
참고: 여기에서는 프로젝트 상황과 관련된 비교적 큰 학습률이 사용됩니다. 실제 프로젝트의 학습률은 일반적으로 매우 낮습니다