Segmentation de mots, étiquetage et découpage de parties de discours
Marquage de séquence en action
RNN bidirectionnel
BI-LSTM-CRF
Attention
Modèles de langage
Modèle unigramme
Modèle bigramme
Modèle trigramme
Modèle RNN de langage
Modèle Transformer de langage
Algèbre linéaire
Vecteur
Matrice
Plonger dans la multiplication matricielle
Tenseur
Construisez et entraînez des réseaux de neurones à partir de zéro
Aperçu
Beaucoup de connaissances théoriques ont été enseignées auparavant, il est maintenant temps de commencer la pratique. Essayons de créer un réseau de neurones à partir de zéro et de l'entraîner pour enchaîner l'ensemble du processus.
Afin d'être plus intuitif et plus facile à comprendre, nous suivons les principes suivants:
N'utilisez pas de bibliothèques tierces pour simplifier la logique;
Pas d'optimisation des performances: évitez d'introduire des concepts et techniques supplémentaires, ce qui augmente la complexité ;
Base de données
Tout d'abord, nous avons besoin d'un ensemble de données. Pour faciliter la visualisation, nous utilisons une fonction binaire comme fonction objectif, puis générons l'ensemble de données en échantillonnant dessus.
Remarque: Dans les projets d'ingénierie réels, la fonction objectif est inconnue, mais nous pouvons l'échantillonner.
Fonction objectif
o(x,y)={10x2+y2<1autrement
Le code s'affiche comme ci-dessous:
defo(x, y):return1.0if x*x + y*y <1else0.0
Générer un ensemble de données
sample_density =10xs =[[-2.0+4* x/sample_density,-2.0+4* y/sample_density]for x inrange(sample_density+1)for y inrange(sample_density+1)]dataset =[(x, y, o(x, y))for x, y in xs
]
L'ensemble de données généré est: [[-2.0, -2,0, 0.0], [-2.0, -1.6, 0.0], ...]
Image de l'ensemble de données
Construire un réseau de neurones
Fonction d'activation
import math
defsigmoid(x):return1/(1+ math.exp(-x))
Neurone
from random import seed, random
seed(0)classNeuron:def__init__(self, num_inputs): self.weights =[random()-0.5for _ inrange(num_inputs)] self.bias =0.0defforward(self, inputs):# z = wx + b z =sum([ i * w
for i, w inzip(inputs, self.weights)])+ self.bias
return sigmoid(z)
L'expression neuronale est:
sigmoid(wx+b)
w: vecteur, correspondant au tableau des poids dans le code
b: correspond au biais dans le code
Remarque: les paramètres du neurone sont initialisés de manière aléatoire. Cependant, afin d'assurer des expériences reproductibles, une graine aléatoire est définie(seed(0))
Les réseaux de neurones
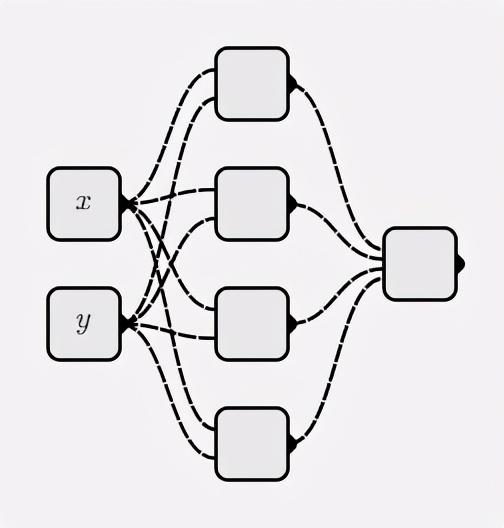
classMyNet:def__init__(self, num_inputs, hidden_shapes): layer_shapes = hidden_shapes +[1] input_shapes =[num_inputs]+ hidden_shapes
self.layers =[[ Neuron(pre_layer_size)for _ inrange(layer_size)]for layer_size, pre_layer_size inzip(layer_shapes, input_shapes)]defforward(self, inputs):for layer in self.layers: inputs =[ neuron.forward(inputs)for neuron in layer
]# return the output of the last neuronreturn inputs[0]
Construisez un réseau de neurones comme suit:
net = MyNet(2,[4])
À ce stade, nous avons un réseau de neurones (net), qui peut appeler sa fonction de réseau de neurones:
print(net.forward([0,0]))
Obtenez la valeur de fonction 0,55..., le réseau de neurones à ce moment est un réseau non formé.
Le calcul du gradient est compliqué, en particulier pour les réseaux de neurones profonds. Back Propagation Algorithm est un algorithme spécialement conçu pour calculer le gradient d'un réseau de neurones.
En raison de sa complexité, il ne sera pas décrit ici. Les personnes intéressées peuvent se référer au code détaillé suivant. De plus, le cadre d'apprentissage profond actuel a pour fonction de calculer automatiquement le gradient.
Trouvez la dérivée partielle (une partie des données est mise en cache dans la fonction forward pour faciliter la dérivée):
classNeuron:...defforward(self, inputs): self.inputs_cache = inputs
# z = wx + b self.z_cache =sum([ i * w
for i, w inzip(inputs, self.weights)])+ self.bias
return sigmoid(self.z_cache)defzero_grad(self): self.d_weights =[0.0for w in self.weights] self.d_bias =0.0defbackward(self, d_a): d_loss_z = d_a * sigmoid_derivative(self.z_cache) self.d_bias += d_loss_z
for i inrange(len(self.inputs_cache)): self.d_weights[i]+= d_loss_z * self.inputs_cache[i]return[d_loss_z * w for w in self.weights]classMyNet:...defzero_grad(self):for layer in self.layers:for neuron in layer: neuron.zero_grad()defbackward(self, d_loss): d_as =[d_loss]for layer inreversed(self.layers): da_list =[ neuron.backward(d_a)for neuron, d_a inzip(layer, d_as)] d_as =[sum(da)for da inzip(*da_list)]
Les dérivées partielles sont stockées dans d_weights et d_bias respectivement
La fonction zero_grad est utilisée pour effacer le gradient, y compris chaque dérivée partielle
La fonction backward est utilisée pour calculer la dérivée partielle et stocker sa valeur cumulativement
Mettre à jour les paramètres
Utilisez la méthode de descente de gradient pour mettre à jour les paramètres:
classNeuron:...defupdate_params(self, learning_rate): self.bias -= learning_rate * self.d_bias
for i inrange(len(self.weights)): self.weights[i]-= learning_rate * self.d_weights[i]classMyNet:...defupdate_params(self, learning_rate):for layer in self.layers:for neuron in layer: neuron.update_params(learning_rate)
Effectuer la formation
defone_step(learning_rate): net.zero_grad() loss =0.0 num_samples =len(dataset)for x, y, z in dataset: predict = net.forward([x, y]) loss += square_loss(predict, z) net.backward(square_loss_derivative(predict, z)/ num_samples) net.update_params(learning_rate)return loss / num_samples
deftrain(epoch, learning_rate):for i inrange(epoch): loss = one_step(learning_rate)if i ==0or(i+1)%100==0:print(f"{i+1}{loss:.4f}")
Formation 2000 étapes:
train(2000, learning_rate=10)
Remarque: Un taux d'apprentissage relativement élevé est utilisé ici, qui est lié à la situation du projet. Le taux d'apprentissage dans les projets réels est généralement très faible
Image de la fonction de réseau neuronal après l'entraînement
log y
La courbe de perte
Inférence
Après la formation, le modèle peut être utilisé pour l'inférence :
Construire une fonction objectif virtuelle: o(x,y);
Échantillonnage sur o(x,y) pour obtenir l'ensemble de données, c'est-à-dire la fonction de l'ensemble de données: d(x,y)
Construit un réseau de neurones entièrement connecté avec une couche cachée, c'est-à-dire une fonction de réseau de neurones: f(x,y)
Utilisez la méthode de descente de gradient pour entraîner le réseau de neurones afin que f(x,y) se rapproche de d(x,y)
La partie la plus compliquée est de trouver le gradient, qui utilise l'algorithme de rétro-propagation. Dans les projets réels, l'utilisation de cadres d'apprentissage en profondeur traditionnels pour le développement peut économiser le code pour les gradients et abaisser le seuil.
Dans les expériences de classification 3D du laboratoire, le deuxième ensemble de données est très similaire à celui de cette pratique, vous pouvez donc y entrer et l'utiliser.