Segmentación de palabras, etiquetado y fragmentación de parte del discurso
Etiquetado de secuencia en acción
RNN bidireccional
BI-LSTM-CRF
Atención
Modelos de lenguaje
Modelo n-grama: Unigrama
Modelo n-grama: Bigrama
Modelo n-grama: Trigrama
Modelo de lenguaje RNN
Modelo de lenguaje Transformer
Álgebra lineal
Vector
Matriz
Sumérgete en la multiplicación de matrices
Tensor
Construya y entrene redes neuronales desde cero
Visión general
Se han contado muchos conocimientos teóricos antes, ahora es el momento de comenzar la práctica. Intentemos construir una red neuronal desde cero y entrenarla para encadenar todo el proceso.
Para ser más intuitivos y fáciles de entender, seguimos los siguientes principios:
No utilice bibliotecas de terceros para simplificar la lógica;
Sin optimización del rendimiento: evite la introducción de conceptos y técnicas adicionales, aumentando la complejidad;
Conjunto de datos
Primero, necesitamos un conjunto de datos. Para facilitar la visualización, usamos una función binaria como función objetivo y luego generamos el conjunto de datos muestreando en él.
Nota: En proyectos de ingeniería reales, la función objetivo es desconocida, pero podemos tomar muestras de ella.
Función objetiva
o(x,y)={10x2+y2<1de lo contrario
El código se muestra a continuación:
defo(x, y):return1.0if x*x + y*y <1else0.0
Generar conjunto de datos
sample_density =10xs =[[-2.0+4* x/sample_density,-2.0+4* y/sample_density]for x inrange(sample_density+1)for y inrange(sample_density+1)]dataset =[(x, y, o(x, y))for x, y in xs
]
El conjunto de datos generado es: [[-2.0, -2.0, 0.0], [-2.0, -1.6, 0.0], ...]
Imagen del conjunto de datos
Construye una red neuronal
Función de activación
import math
defsigmoid(x):return1/(1+ math.exp(-x))
Neurona
from random import seed, random
seed(0)classNeuron:def__init__(self, num_inputs): self.weights =[random()-0.5for _ inrange(num_inputs)] self.bias =0.0defforward(self, inputs):# z = wx + b z =sum([ i * w
for i, w inzip(inputs, self.weights)])+ self.bias
return sigmoid(z)
La expresión de la neurona es:
sigmoid(wx+b)
w: vector, correspondiente a la matriz de pesos en el código
b: corresponde al sesgo en el código
Nota: Los parámetros de la neurona se inicializan aleatoriamente. Sin embargo, para garantizar experimentos reproducibles, se establece una semilla aleatoria (seed(0))
Redes neuronales
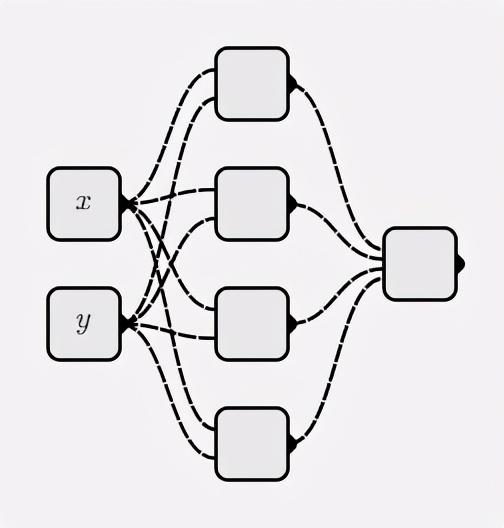
classMyNet:def__init__(self, num_inputs, hidden_shapes): layer_shapes = hidden_shapes +[1] input_shapes =[num_inputs]+ hidden_shapes
self.layers =[[ Neuron(pre_layer_size)for _ inrange(layer_size)]for layer_size, pre_layer_size inzip(layer_shapes, input_shapes)]defforward(self, inputs):for layer in self.layers: inputs =[ neuron.forward(inputs)for neuron in layer
]# devuelve la salida de la última neuronareturn inputs[0]
Construya una red neuronal de la siguiente manera:
net = MyNet(2,[4])
En este punto, tenemos una red neuronal (net), que puede llamar a su función de red neuronal:
print(net.forward([0,0]))
Obtenga el valor de la función 0.55 ..., la red neuronal en este momento es una red no capacitada.
El cálculo del gradiente es complicado, especialmente para redes neuronales profundas. Back Propagation Algorithm es un algoritmo diseñado específicamente para calcular el gradiente de una red neuronal.
Debido a su complejidad, no se describirá aquí. Los interesados pueden consultar el siguiente código detallado. Además, el marco actual de aprendizaje profundo tiene la función de calcular automáticamente el gradiente.
Encuentre la derivada parcial (parte de los datos se almacena en caché en la función de avance para facilitar la derivada):
classNeuron:...defforward(self, inputs): self.inputs_cache = inputs
# z = wx + b self.z_cache =sum([ i * w
for i, w inzip(inputs, self.weights)])+ self.bias
return sigmoid(self.z_cache)defzero_grad(self): self.d_weights =[0.0for w in self.weights] self.d_bias =0.0defbackward(self, d_a): d_loss_z = d_a * sigmoid_derivative(self.z_cache) self.d_bias += d_loss_z
for i inrange(len(self.inputs_cache)): self.d_weights[i]+= d_loss_z * self.inputs_cache[i]return[d_loss_z * w for w in self.weights]classMyNet:...defzero_grad(self):for layer in self.layers:for neuron in layer: neuron.zero_grad()defbackward(self, d_loss): d_as =[d_loss]for layer inreversed(self.layers): da_list =[ neuron.backward(d_a)for neuron, d_a inzip(layer, d_as)] d_as =[sum(da)for da inzip(*da_list)]
Las derivadas parciales se almacenan en d_weights y d_bias respectivamente
La función zero_grad se usa para borrar el gradiente, incluida cada derivada parcial
La función backward se utiliza para calcular la derivada parcial y almacenar su valor de forma acumulativa
Actualizar parámetros
Utilice el método de descenso de gradiente para actualizar los parámetros:
classNeuron:...defupdate_params(self, learning_rate): self.bias -= learning_rate * self.d_bias
for i inrange(len(self.weights)): self.weights[i]-= learning_rate * self.d_weights[i]classMyNet:...defupdate_params(self, learning_rate):for layer in self.layers:for neuron in layer: neuron.update_params(learning_rate)
Realizar entrenamiento
defone_step(learning_rate): net.zero_grad() loss =0.0 num_samples =len(dataset)for x, y, z in dataset: predict = net.forward([x, y]) loss += square_loss(predict, z) net.backward(square_loss_derivative(predict, z)/ num_samples) net.update_params(learning_rate)return loss / num_samples
deftrain(epoch, learning_rate):for i inrange(epoch): loss = one_step(learning_rate)if i ==0or(i+1)%100==0:print(f"{i+1}{loss:.4f}")
Entrenamiento 2000 pasos:
train(2000, learning_rate=10)
Nota: Aquí se utiliza una tasa de aprendizaje relativamente grande, que está relacionada con la situación del proyecto. La tasa de aprendizaje en proyectos reales suele ser muy pequeña
Imagen de la función de red neuronal después del entrenamiento
log y
La curva de pérdidas
Inferencia
Después del entrenamiento, el modelo se puede utilizar para la inferencia:
Muestreo de o(x,y) para obtener el conjunto de datos, es decir, la función del conjunto de datos: d(x,y)
Construyó una red neuronal completamente conectada con una capa oculta, es decir, función de red neuronal: f(x,y)
Utilice el método de descenso de gradiente para entrenar la red neuronal de modo que f(x,y) se aproxime a d(x,y)
La parte más complicada es encontrar el gradiente, que utiliza el algoritmo de retropropagación. En proyectos reales, el uso de marcos de aprendizaje profundo convencionales para el desarrollo puede ahorrar el código para gradientes y reducir el umbral.
En los experimentos de clasificación 3D del laboratorio, el segundo conjunto de datos es muy similar al de esta práctica, por lo que puede ingresar y operarlo.