Verschwindender Gradient und explodierender Gradient
Convolutional Neural Network (CNN)
1D-Faltung
1D-Faltungsexperimente
1D-Pooling
1D-CNN-Experimente
2D-CNN
2D-CNN Experimente
Rekurrentes neuronales Netz (RNN)
Vanille RNN
Seq2seq, Autoencoder, Encoder-Decoder
Erweiterte RNN
RNN-Klassifikationsexperiment
Verarbeitung natürlicher Sprache
Embedding: Symbole in Werte umwandeln
Textkategorisierung 1
Textkategorisierung 2
TextCNN
Entitätserkennung
Wortsegmentierung, Wortart-Tagging und Chunking
Sequenz-Tagging in Aktion
Bidirektionales RNN
BI-LSTM-CRF
Beachtung
Sprachmodelle
n-gram-Modelle: Unigram
n-gram-Modelle: Bigram
n-gram-Modelle: Trigram
RNN-Sprachmodelle
Transformer-Sprachmodelle
Lineare Algebra
Vektor
Matrix
Eintauchen in die Matrixmultiplikation
Tensor
Erstellen und trainieren Sie neuronale Netze von Grund auf neu
Überblick
Viel theoretisches Wissen wurde vorher schon erzählt, jetzt ist es an der Zeit mit der Praxis zu beginnen. Lassen Sie uns versuchen, ein neuronales Netzwerk von Grund auf neu aufzubauen und es zu trainieren, um den gesamten Prozess aneinanderzureihen.
Um intuitiver und verständlicher zu sein, folgen wir den folgenden Prinzipien:
Verwenden Sie keine Bibliotheken von Drittanbietern, um die Logik zu vereinfachen;
Keine Leistungsoptimierung: Vermeiden Sie die Einführung zusätzlicher Konzepte und Techniken, die die Komplexität erhöhen;
Datensatz
Zuerst benötigen wir einen Datensatz. Um die Visualisierung zu erleichtern, verwenden wir eine binäre Funktion als Zielfunktion und generieren dann den Datensatz, indem wir darauf sampeln.
Hinweis: In tatsächlichen Engineering-Projekten ist die Zielfunktion unbekannt, aber wir können sie beproben.
Zielfunktion
o(x,y)={10x2+y2<1sonst
Code-Show wie folgt:
defo(x, y):return1.0if x*x + y*y <1else0.0
Datensatz generieren
sample_density =10xs =[[-2.0+4* x/sample_density,-2.0+4* y/sample_density]for x inrange(sample_density+1)for y inrange(sample_density+1)]dataset =[(x, y, o(x, y))for x, y in xs
]
import math
defsigmoid(x):return1/(1+ math.exp(-x))
Neuron
from random import seed, random
seed(0)classNeuron:def__init__(self, num_inputs): self.weights =[random()-0.5for _ inrange(num_inputs)] self.bias =0.0defforward(self, inputs):# z = wx + b z =sum([ i * w
for i, w inzip(inputs, self.weights)])+ self.bias
return sigmoid(z)
Der Neuronenausdruck lautet:
sigmoid(wx+b)
w: Vektor, entsprechend dem Gewichtungs-Array im Code
b: entspricht dem Bias im Code
Hinweis: Die Parameter im Neuron werden zufällig initialisiert. Um jedoch reproduzierbare Experimente zu gewährleisten, wird ein zufälliger Seed gesetzt(seed(0))
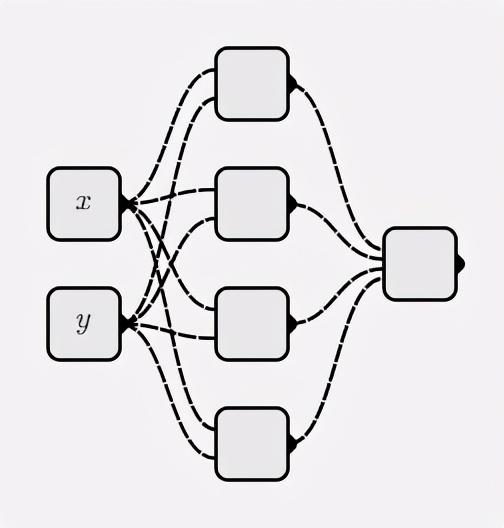
Neuronale Netze
classMyNet:def__init__(self, num_inputs, hidden_shapes): layer_shapes = hidden_shapes +[1] input_shapes =[num_inputs]+ hidden_shapes
self.layers =[[ Neuron(pre_layer_size)for _ inrange(layer_size)]for layer_size, pre_layer_size inzip(layer_shapes, input_shapes)]defforward(self, inputs):for layer in self.layers: inputs =[ neuron.forward(inputs)for neuron in layer
]# die Ausgabe des letzten Neurons zurückgebenreturn inputs[0]
Konstruieren Sie ein neuronales Netz wie folgt:
net = MyNet(2,[4])
An dieser Stelle haben wir ein neuronales Netz (Netz), das seine neuronale Netzfunktion aufrufen kann:
print(net.forward([0,0]))
Holen Sie sich den Funktionswert 0.55..., das neuronale Netz ist zu diesem Zeitpunkt ein untrainiertes Netz.
Die Berechnung des Gradienten ist insbesondere bei tiefen neuronalen Netzen kompliziert. Back-Propagation-Algorithmus ist ein Algorithmus, der speziell entwickelt wurde, um den Gradienten eines neuronalen Netzes zu berechnen.
Aufgrund seiner Komplexität wird es hier nicht beschrieben. Interessierte können auf den folgenden detaillierten Code verweisen. Darüber hinaus hat das aktuelle Deep-Learning-Framework die Funktion, den Gradienten automatisch zu berechnen.
Finden Sie die partielle Ableitung (ein Teil der Daten wird in der Vorwärtsfunktion zwischengespeichert, um die Ableitung zu erleichtern):
classNeuron:...defforward(self, inputs): self.inputs_cache = inputs
# z = wx + b self.z_cache =sum([ i * w
for i, w inzip(inputs, self.weights)])+ self.bias
return sigmoid(self.z_cache)defzero_grad(self): self.d_weights =[0.0for w in self.weights] self.d_bias =0.0defbackward(self, d_a): d_loss_z = d_a * sigmoid_derivative(self.z_cache) self.d_bias += d_loss_z
for i inrange(len(self.inputs_cache)): self.d_weights[i]+= d_loss_z * self.inputs_cache[i]return[d_loss_z * w for w in self.weights]classMyNet:...defzero_grad(self):for layer in self.layers:for neuron in layer: neuron.zero_grad()defbackward(self, d_loss): d_as =[d_loss]for layer inreversed(self.layers): da_list =[ neuron.backward(d_a)for neuron, d_a inzip(layer, d_as)] d_as =[sum(da)for da inzip(*da_list)]
Partielle Ableitungen werden in d_weights bzw. d_bias gespeichert
Die Funktion zero_grad wird verwendet, um den Gradienten zu löschen, einschließlich jeder partiellen Ableitung
Die Funktion backward wird verwendet, um die partielle Ableitung zu berechnen und ihren Wert kumulativ zu speichern
Parameter aktualisieren
Verwenden Sie die Gradientenabstiegsmethode, um Parameter zu aktualisieren:
classNeuron:...defupdate_params(self, learning_rate): self.bias -= learning_rate * self.d_bias
for i inrange(len(self.weights)): self.weights[i]-= learning_rate * self.d_weights[i]classMyNet:...defupdate_params(self, learning_rate):for layer in self.layers:for neuron in layer: neuron.update_params(learning_rate)
Training durchführen
defone_step(learning_rate): net.zero_grad() loss =0.0 num_samples =len(dataset)for x, y, z in dataset: predict = net.forward([x, y]) loss += square_loss(predict, z) net.backward(square_loss_derivative(predict, z)/ num_samples) net.update_params(learning_rate)return loss / num_samples
deftrain(epoch, learning_rate):for i inrange(epoch): loss = one_step(learning_rate)if i ==0or(i+1)%100==0:print(f"{i+1}{loss:.4f}")
Training 2000 Schritte:
train(2000, learning_rate=10)
Hinweis: Hier wird eine relativ große Lernrate verwendet, die sich auf die Projektsituation bezieht. Die Lernrate in konkreten Projekten ist meist sehr gering
Bild der neuronalen Netzfunktion nach dem Training
log y
Die Verlustkurve
Inferenz
Nach dem Training kann das Modell zur Inferenz verwendet werden:
Konstruieren Sie eine virtuelle Zielfunktion: o(x,y);
Sampling auf o(x,y) um den Datensatz zu erhalten, d.h. die Datensatzfunktion: d(x,y)
Konstruierte ein vollständig verbundenes neuronales Netzwerk mit einer versteckten Schicht, d. h. einer neuronalen Netzwerkfunktion: f(x,y)
Verwenden Sie die Gradientenabstiegsmethode, um das neuronale Netz so zu trainieren, dass f(x,y) ungefähr d(x,y) . entspricht
Der komplizierteste Teil besteht darin, den Gradienten zu finden, der den Backpropagation-Algorithmus verwendet. In tatsächlichen Projekten kann die Verwendung von Mainstream-Deep-Learning-Frameworks für die Entwicklung den Code für Gradienten speichern und den Schwellenwert senken.
In den 3D-Klassifizierung-Experimenten des Labors ist der zweite Datensatz dem in dieser Praxis sehr ähnlich, sodass Sie ihn ausführen und bedienen können.