Ранее было рассказано много теоретических знаний, теперь пора приступить к практике. Давайте попробуем построить нейронную сеть с нуля и научим ее связывать весь процесс воедино.
Чтобы быть более интуитивным и понятным, мы следуем следующим принципам:
Не используйте сторонние библиотеки для упрощения логики;
Отсутствие оптимизации производительности: избегайте введения дополнительных концепций и методов, увеличивающих сложность;
Набор данных
Во-первых, нам нужен набор данных. Чтобы облегчить визуализацию, мы используем двоичную функцию в качестве целевой функции, а затем генерируем набор данных путем выборки на нем.
Примечание: в реальных инженерных проектах целевая функция неизвестна, но мы можем использовать ее для выборки.
Целевая функция
o(x,y)={10x2+y2<1иначе
Код показан ниже:
defo(x, y):return1.0if x*x + y*y <1else0.0
Создать набор данных
sample_density =10xs =[[-2.0+4* x/sample_density,-2.0+4* y/sample_density]for x inrange(sample_density+1)for y inrange(sample_density+1)]dataset =[(x, y, o(x, y))for x, y in xs
]
Созданный набор данных: [[-2.0, -2.0, 0.0], [-2.0, -1.6, 0.0], ...]
Изображение набора данных
Построить нейронную сеть
Функция активации
import math
defsigmoid(x):return1/(1+ math.exp(-x))
Нейрон
from random import seed, random
seed(0)classNeuron:def__init__(self, num_inputs): self.weights =[random()-0.5for _ inrange(num_inputs)] self.bias =0.0defforward(self, inputs):# z = wx + b z =sum([ i * w
for i, w inzip(inputs, self.weights)])+ self.bias
return sigmoid(z)
Выражение нейрона:
sigmoid(wx+b)
w: вектор, соответствующий массиву весов в коде
b: соответствует смещению в коде
Примечание: параметры нейрона инициализируются случайным образом. Однако для обеспечения воспроизводимости экспериментов устанавливается случайное начальное число (seed(0))
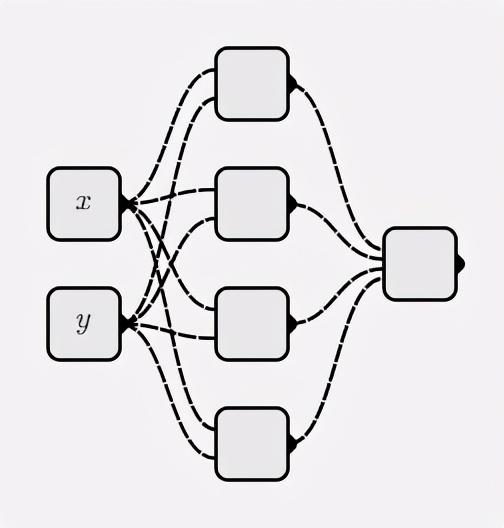
Нейронные сети
classMyNet:def__init__(self, num_inputs, hidden_shapes): layer_shapes = hidden_shapes +[1] input_shapes =[num_inputs]+ hidden_shapes
self.layers =[[ Neuron(pre_layer_size)for _ inrange(layer_size)]for layer_size, pre_layer_size inzip(layer_shapes, input_shapes)]defforward(self, inputs):for layer in self.layers: inputs =[ neuron.forward(inputs)for neuron in layer
]# return the output of the last neuronreturn inputs[0]
Постройте нейронную сеть следующим образом:
net = MyNet(2,[4])
На данный момент у нас есть нейронная сеть (сеть), которая может вызывать свою функцию нейронной сети:
print(net.forward([0,0]))
Получите значение функции 0,55 ..., нейронная сеть на данный момент является необученной сетью.
Расчет градиента сложен, особенно для глубоких нейронных сетей. Алгоритм обратного распространения - это алгоритм, специально разработанный для расчета градиента нейронной сети.
Из-за своей сложности здесь описываться не будет. Желающие могут обратиться к следующему подробному коду. Более того, текущая структура глубокого обучения имеет функцию автоматического вычисления градиента.
Найдите частную производную (часть данных кэшируется в прямой функции, чтобы облегчить производную):
classNeuron:...defforward(self, inputs): self.inputs_cache = inputs
# z = wx + b self.z_cache =sum([ i * w
for i, w inzip(inputs, self.weights)])+ self.bias
return sigmoid(self.z_cache)defzero_grad(self): self.d_weights =[0.0for w in self.weights] self.d_bias =0.0defbackward(self, d_a): d_loss_z = d_a * sigmoid_derivative(self.z_cache) self.d_bias += d_loss_z
for i inrange(len(self.inputs_cache)): self.d_weights[i]+= d_loss_z * self.inputs_cache[i]return[d_loss_z * w for w in self.weights]classMyNet:...defzero_grad(self):for layer in self.layers:for neuron in layer: neuron.zero_grad()defbackward(self, d_loss): d_as =[d_loss]for layer inreversed(self.layers): da_list =[ neuron.backward(d_a)for neuron, d_a inzip(layer, d_as)] d_as =[sum(da)for da inzip(*da_list)]
Частные производные хранятся в d_weights и d_bias соответственно
Функция zero_grad используется для очистки градиента, включая каждую частную производную
Функция backward используется для вычисления частной производной и накопления ее значения.
Обновить параметры
Используйте метод градиентного спуска для обновления параметров:
classNeuron:...defupdate_params(self, learning_rate): self.bias -= learning_rate * self.d_bias
for i inrange(len(self.weights)): self.weights[i]-= learning_rate * self.d_weights[i]classMyNet:...defupdate_params(self, learning_rate):for layer in self.layers:for neuron in layer: neuron.update_params(learning_rate)
Выполните обучение
defone_step(learning_rate): net.zero_grad() loss =0.0 num_samples =len(dataset)for x, y, z in dataset: predict = net.forward([x, y]) loss += square_loss(predict, z) net.backward(square_loss_derivative(predict, z)/ num_samples) net.update_params(learning_rate)return loss / num_samples
deftrain(epoch, learning_rate):for i inrange(epoch): loss = one_step(learning_rate)if i ==0or(i+1)%100==0:print(f"{i+1}{loss:.4f}")
Обучение 2000 шагов:
train(2000, learning_rate=10)
Примечание: здесь используется относительно большая скорость обучения, что связано с ситуацией в проекте. Скорость обучения в реальных проектах обычно очень мала
Изображение функции нейросети после обучения
log y
Кривая потерь
Вывод
После обучения модель можно использовать для вывода:
Выборка на o(x,y) для получения набора данных, то есть функции набора данных: d(x,y)
Построена полносвязная нейронная сеть со скрытым слоем, то есть функция нейронной сети: f(x,y)
Используйте метод градиентного спуска для обучения нейронной сети так, чтобы f(x,y) приближалось d(x,y)
Самая сложная часть - найти градиент, который использует алгоритм обратного распространения. В реальных проектах использование основных фреймворков глубокого обучения для разработки может сохранить код для градиентов и снизить порог.
В лабораторных экспериментах 3D классификация второй набор данных очень похож на тот, который используется в этой практике, так что вы можете войти и использовать его.