Segmentazione delle parole, tag e suddivisione in parti del discorso
Tag di sequenza in azione
RNN Bi bidirezionale
BI-LSTM-CRF
Attenzione
Modelli di linguaggio
Modello n-gram: Unigram
Modello n-gram: Bigram
Modello n-gram: Trigram
Modello RNN
Modello Transformer
Algebra lineare
Vettore
Matrice
Immergiti nella moltiplicazione di matrici
Tensore
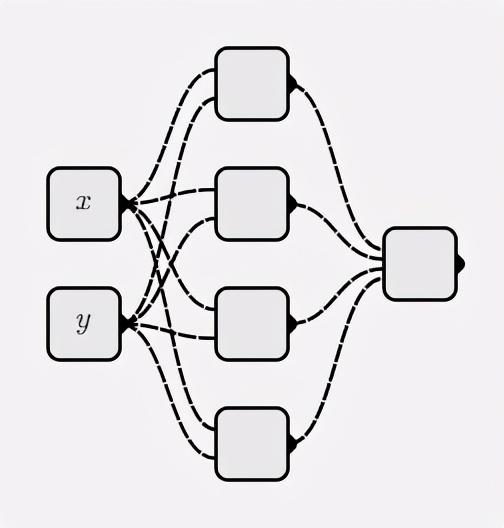
Costruisci e addestra reti neurali da zero
Panoramica
Molte conoscenze teoriche sono state raccontate prima, ora è il momento di iniziare la pratica. Proviamo a costruire una rete neurale da zero e ad addestrarla a mettere insieme l'intero processo.
Per essere più intuitivi e di facile comprensione, seguiamo i seguenti principi:
Non utilizzare librerie di terze parti per semplificare la logica;
Nessuna ottimizzazione delle prestazioni: evita di introdurre concetti e tecniche aggiuntivi, aumentando la complessità;
set di dati
Innanzitutto, abbiamo bisogno di un set di dati. Per facilitare la visualizzazione, utilizziamo una funzione binaria come funzione obiettivo, quindi generiamo il set di dati campionandolo.
Nota: nei progetti di ingegneria reali, la funzione obiettivo è sconosciuta, ma possiamo campionarla.
Funzione obiettivo
o(x,y)={10x2+y2<1else
Il codice mostra come di seguito:
defo(x, y):return1.0if x*x + y*y <1else0.0
Genera set di dati
sample_density =10xs =[[-2.0+4* x/sample_density,-2.0+4* y/sample_density]for x inrange(sample_density+1)for y inrange(sample_density+1)]dataset =[(x, y, o(x, y))for x, y in xs
]
Il set di dati generato è: [[-2.0, -2.0, 0.0], [-2.0, -1.6, 0.0], ...]
Immagine del set di dati
Costruisci una rete neurale
Funzione di attivazione
import math
defsigmoid(x):return1/(1+ math.exp(-x))
Neurone
from random import seed, random
seed(0)classNeuron:def__init__(self, num_inputs): self.weights =[random()-0.5for _ inrange(num_inputs)] self.bias =0.0defforward(self, inputs):# z = wx + b z =sum([ i * w
for i, w inzip(inputs, self.weights)])+ self.bias
return sigmoid(z)
L'espressione del neurone è:
sigmoid(wx+b)
w: vettore, corrispondente all'array dei pesi nel codice
b: corrisponde alla distorsione nel codice
Nota: i parametri nel neurone vengono inizializzati casualmente. Tuttavia, per garantire la riproducibilità degli esperimenti, viene impostato un seme casuale(seed(0))
Il calcolo del gradiente è complicato, soprattutto per le reti neurali profonde. Back Propagation Algorithm è un algoritmo progettato specificamente per calcolare il gradiente di una rete neurale.
A causa della sua complessità, non verrà qui descritto. Gli interessati possono fare riferimento al seguente codice dettagliato. Inoltre, l'attuale framework di deep learning ha la funzione di calcolare automaticamente il gradiente.
Trova la derivata parziale (parte dei dati è memorizzata nella cache nella funzione forward per facilitare la derivata):
classNeuron:...defforward(self, inputs): self.inputs_cache = inputs
# z = wx + b self.z_cache =sum([ i * w
for i, w inzip(inputs, self.weights)])+ self.bias
return sigmoid(self.z_cache)defzero_grad(self): self.d_weights =[0.0for w in self.weights] self.d_bias =0.0defbackward(self, d_a): d_loss_z = d_a * sigmoid_derivative(self.z_cache) self.d_bias += d_loss_z
for i inrange(len(self.inputs_cache)): self.d_weights[i]+= d_loss_z * self.inputs_cache[i]return[d_loss_z * w for w in self.weights]classMyNet:...defzero_grad(self):for layer in self.layers:for neuron in layer: neuron.zero_grad()defbackward(self, d_loss): d_as =[d_loss]for layer inreversed(self.layers): da_list =[ neuron.backward(d_a)for neuron, d_a inzip(layer, d_as)] d_as =[sum(da)for da inzip(*da_list)]
Le derivate parziali sono memorizzate rispettivamente in d_weights e d_bias
La funzione zero_grad viene utilizzata per cancellare il gradiente, inclusa ogni derivata parziale
La funzione indietro viene utilizzata per calcolare la derivata parziale e memorizzare il suo valore cumulativamente
Aggiorna parametri
Usa il metodo di discesa del gradiente per aggiornare i parametri:
classNeuron:...defupdate_params(self, learning_rate): self.bias -= learning_rate * self.d_bias
for i inrange(len(self.weights)): self.weights[i]-= learning_rate * self.d_weights[i]classMyNet:...defupdate_params(self, learning_rate):for layer in self.layers:for neuron in layer: neuron.update_params(learning_rate)
Esegui l'allenamento
defone_step(learning_rate): net.zero_grad() loss =0.0 num_samples =len(dataset)for x, y, z in dataset: predict = net.forward([x, y]) loss += square_loss(predict, z) net.backward(square_loss_derivative(predict, z)/ num_samples) net.update_params(learning_rate)return loss / num_samples
deftrain(epoch, learning_rate):for i inrange(epoch): loss = one_step(learning_rate)if i ==0or(i+1)%100==0:print(f"{i+1}{loss:.4f}")
Formazione 2000 fasi:
train(2000, learning_rate=10)
Nota: qui viene utilizzato un tasso di apprendimento relativamente elevato, che è correlato alla situazione del progetto. Il tasso di apprendimento nei progetti reali è solitamente molto basso
Immagine della funzione di rete neurale dopo l'allenamento
log y
La curva delle perdite
Inferenza
Dopo l'allenamento, il modello può essere utilizzato per l'inferenza:
Costruire una funzione obiettivo virtuale: o(x,y);
Campionamento su o(x,y) per ottenere il set di dati, ovvero la funzione del set di dati: d(x,y)
Costruito una rete neurale completamente connessa con un livello nascosto, ovvero una funzione di rete neurale: f(x,y)
Utilizzare il metodo di discesa del gradiente per addestrare la rete neurale in modo che f(x,y) si avvicini a d(x,y)
La parte più complicata è trovare il gradiente, che utilizza l'algoritmo di retropropagazione. Nei progetti reali, l'utilizzo di framework di deep learning tradizionali per lo sviluppo può salvare il codice per i gradienti e abbassare la soglia.
Negli esperimenti di classificazione 3D del laboratorio, il secondo set di dati è molto simile a quello di questa pratica, quindi puoi entrare e utilizzarlo.